Welcome to our newsletter, posit::glimpse()!
If you’re currently reading this on our blog, consider subscribing to Product Updates - Open Source on our subscription page to receive this newsletter directly in your inbox.
Welcome to the latest edition of the posit::glimpse() newsletter, the monthly roundup of open-source news for the Posit community. I have many updates for you from across Posit. As my wonderful colleague Kristin Bott stated, “dang this is a productive bunch of humans”.
The table of contents on the right can help you navigate through all the updates. As you scroll, it will open up to show you subcategories →
Announcements#
posit::conf(2026) is happening soon!#
Our annual conference, posit::conf(2026), is happening September 14-16, and we would love to see you there, whether in Houston or online! Check out the speaker lineup, workshop offerings, and register for posit::conf here.
Tidy Dev Day is happening on September 17, a unique opportunity to collaboratively tackle open-source issues and work directly alongside the very developers who build and maintain the tools you use every day. As Meghan Harris stated about last year’s event, “Tidy Dev Day (TDD) gave me the PERFECT opportunity to explore this further in a low-stress, supportive environment.” Learn more about Tidy Dev Day here.
We’ve joined the Jupyter Foundation#
We are proud to announce that we are deepening our commitment to the Jupyter ecosystem by becoming an official Jupyter Foundation Member!
Announcing an expanded Posit Academy#
We’ve launched a new part of Posit Academy: a free, open library of product courses, hands-on labs, and live workshops available to anyone.
Introducing the Posit Impact Awards#
Have a story to share? We just launched the Posit Impact Awards to recognize individuals and teams who used Posit to create measurable, meaningful change. Six winners will be selected, one per category, and each will receive a conference-only pass to posit::conf(2026).
Key product updates and new releases#
Data visualization and reporting#
ggsql 0.4.1#
ggsql 0.4.1 introduces spatial plotting capabilities with database-backed geometry processing, supporting WKB format data, 21 map projections for cartographic accuracy, and a built-in Natural Earth world dataset for creating choropleth maps and geographic visualizations with backends like DuckDB spatial, PostGIS, and SpatiaLite.
Ask more of your dashboard with querychat and ggsql#
querychat now supports ggsql-powered visualizations, enabling natural language data exploration in dashboards through SQL-only execution (no arbitrary code), with three pre-built tools for visualizing, querying, and filtering data reactively. The package works in both Python and R, integrates with Shiny dashboards, and supports Snowflake Semantic Models for business logic definitions.
Great Tables 0.22.0#
Great Tables v0.22.0 significantly expands Python table presentation capabilities with footnote support, group-wise and grand summary row calculations, column merging utilities for uncertainty and ranges, text transformation methods, value substitution helpers, duration and parts-per formatters, image export functionality via gtsave(), enhanced LaTeX rendering, and makes Pandas an optional dependency for Polars-only workflows. (impressive update!)
Data access#
dbplyr 2.6.0#
dbplyr 2.6.0 introduces ADBC support via adbi for faster Arrow-based data transfer, JDBC support, new SQL dialect separation, and query composition functions.
webR 0.6.0#
webR 0.6.0 upgrades to R 4.6.0 and adds async/await support for JavaScript Promises, curl and httr2 compatibility through WebSocket traffic proxying, modern Fortran fixes for expanded package support, and updated system libraries including OpenSSL 3.5.1 and Emscripten 5.0.7. The release powers interactive R experiences in Quarto Live and Shinylive.
debrief 0.1.0#
The debrief package converts profvis profiling output into text-based summaries designed for AI agents, enabling AI-assisted performance optimization by providing structured reports on hotspots, call trees, and memory allocations that AI systems can read and act upon.
pkgsite 0.1.0#
pkgsite 0.1.0 converts R package .Rd documentation files into Quarto .qmd files, enabling custom documentation sites with Quarto’s freeze feature for local example rendering, unified R/Python documentation when combined with Quartodoc, and flexible template customization. The package is available on CRAN and provides an alternative to pkgdown.
watcher 0.2.0#
Watcher is a lightweight R package that watches files and directories for changes and reacts in the background. It’s quietly been the engine behind Shiny’s auto-reload for the past year. With the CRAN release of 0.2.0, we’re excited to introduce it as a general-purpose filesystem watcher for R developers.
Development environment#
Air 0.10.0#
Air 0.10.0 introduces configurable assignment style enforcement allowing teams to standardize on arrow (<-), equal (=), or preserve existing styles, along with enhanced IDE integrations for Positron and RStudio, multiple installation methods via PyPI and conda-forge, pre-commit hook support, stdin integration for editors, and shell completions.
What’s new in Positron#
Positron’s June release includes a lot of highly requested features:
- Inline output for Quarto (one of Positron’s most-requested features ever!)
- Posit Assistant, the successor to Positron Assistant
- Packages pane improvements
- A more customizable interface
For more, check out the Positron June Release Highlights post and subscribe to Positron emails.
Did you know that many of the most upvoted RStudio feature requests are already implemented in Positron? Learn about ten of them in the RStudio’s Top Feature Requests … In Positron blog post!
Machine learning and modeling#
brulee 1.0.0#
brulee 1.0.0 significantly expands tabular deep learning capabilities in R with five new model architectures, GPU support including Apple Silicon, 32-bit precision for improved performance, and enhanced numerical stability, all integrated with the tidymodels ecosystem.
CatBoost support in tidymodels#
CatBoost gradient boosting support is now available in tidymodels through the boost_tree() interface, providing access to CatBoost’s strong categorical feature handling with full tidymodels integration including hyperparameter tuning, cross-validation, efficient submodel optimization, and orbital package support for SQL generation and in-database predictions.
tidyclust 0.3.0#
tidyclust 0.3.0 introduces three new clustering model families and achieves full integration with tidymodels by replacing tidyclust-specific functions with native tune package support.
Event roundup#
We were all over the world this month, discussing how to adopt new data tools, get better at old ones, and just loving being part of the community. If you want to learn more about where we were, or see where we’ll be next, check out our event page.
Watch the recordings from some of these events:
Jun 15, 2026
|
34 min
|
221 views
Neal Richardson - MCP, or not MCP | Pydata London 26
Neal Richardson - MCP, or not MCP | Pydata London 26 \Model Context Protocol is a standard for defining tools that can be made available to LLMs and AI applications. There’s a lot of noise out there about what you should use to get the best results from AI, so in this talk, I will provide some guidance on when you should use MCP, and when you should reach for some other tool. I will describe cases where MCP is the right tool for the job, and when other things, like skills or other context files, are better. I will also devote attention to questions of security and authentication, which are important for MCP, and provide concrete examples of how MCP servers can be used to unlock agentic workflows while also strengthening data governance. This talk is intended for those who are interested in using LLMs for workflows involving data. No prior experience with MCP is required.
Outline:
Intro: how can I get data from this API into my Claude Code session? What is MCP? When should you use it, when should you use other tools Work through an example Sharing and deploying MCP servers, alternatives and best practices Optimizing your tools for best results www.pydata.org
PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organization in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The global PyData network promotes discussion of best practices, new approaches, and emerging technologies for data management, processing, analytics, and visualization. PyData communities approach data science using many languages, including (but not limited to) Python, Julia, and R.
PyData conferences aim to be accessible and community-driven, with novice to advanced level presentations. PyData tutorials and talks bring attendees the latest project features along with cutting-edge use cases.
00:00 Welcome! 00:10 Help us add time stamps or captions to this video! See the description for details.
Want to help add timestamps to our YouTube videos to help with discoverability? Find out more here: https://github.com/numfocus/YouTubeVideoTimestamps
Python
Tutorial
Education
NumFOCUS
PyData
Opensource
Learn
Software
Python 3
Julia
Coding
Learn to Code
How to Program
Scientific Programming
Jun 26, 2026
|
47 min
|
29 views
Agents for Correct, Transparent, and Reproducible Data Analysis - Simon Couch & Sara Altman
Agents for Correct, Transparent, and Reproducible Data Analysis - Simon Couch & Sara Altman (Posit)
Abstract: How do we build competent data analysis agents? Data analysis requires a willingness to pause, question conclusions, and dig into subtleties. Frontier LLMs, however, are optimized to push tasks toward completion, not to slow down when something seems off. This tendency works well for coding agents, where success is often verifiable. But for data analysis, verification is more complicated, and autonomous work by the agent can be at odds with the spirit of the discipline. Drawing on our experience building data analysis agents, we’ll share evaluations that expose where LLM-driven analysis goes wrong and design patterns that keep analyses correct, transparent, and reproducible.
Resources mentioned in the session:
Presentation Slides: https://simonpcouch.github.io/gen-ai-pharma-26 Presentation GitHub repository: https://github.com/simonpcouch/gen-ai-pharma-26 bluffbench: https://github.com/simonpcouch/bluffbench Posit Assistant Terminal (TUI): https://posit-dev.github.io/assistant/docs/downloads/tui/ Posit AI Newsletter: https://opensource.posit.co/tags/ai-newsletter/ Speakers:
Simon Couch builds tools that make the work of data science more joyful and effective. As an engineer on the AI Core Team at Posit, his work spans coding agents, model evaluations, inference engineering, and next-edit-suggestion systems. Drawing on his background in statistics, Simon spent several years authoring and maintaining core packages in the open-source tidymodels framework—like stacks, broom, and infer — before shifting his focus to LLMs. He blogs about his work at simonpcouch.com. Simon authors the Posit AI Newsletter along with Sara Altman.
Sara Altman is a Senior Developer Advocate on the AI Core team at Posit, where she focuses on how AI can be effectively and responsibly used for data science. Previously, she helped build Posit Academy and taught data science and R at Stanford. Sara authors the Posit AI Newsletter along with Simon Couch.
Presented at the 2026 R/Pharma GenAI Day
infer
tidymodels
Brilliant Earth turned their Marketing Mix Model into a Streamlit app deployed on Posit Connect via the Snowflake Native App, so their marketing team can dig into channel performance and run scenario planning on their own. One of the campaigns in the mix: their recent Ring Pop collaboration.
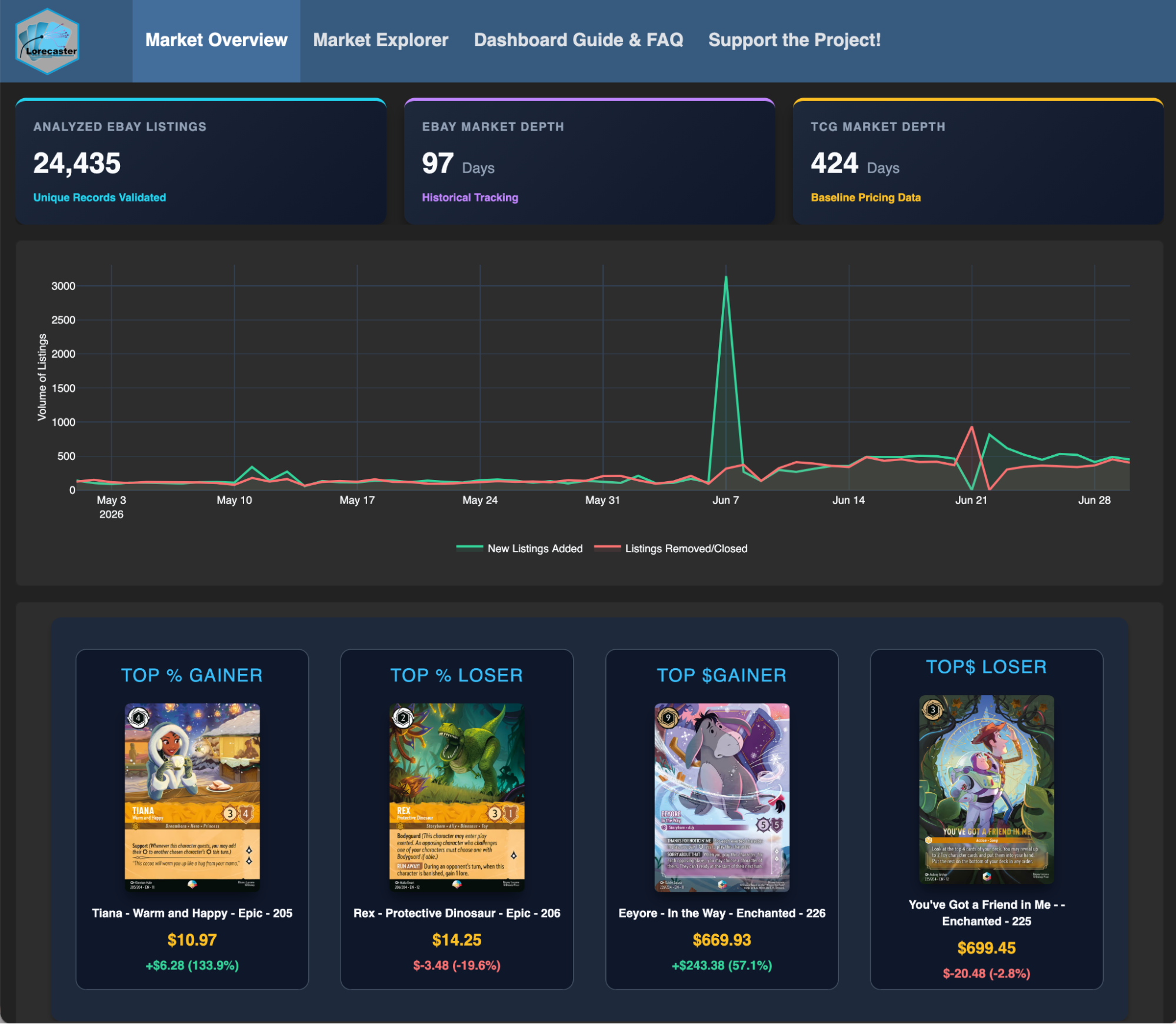
Leo Ohyama recently shared a fantastic Lorcana Market Data Analysis & Forecasting dashboard that showcases the power of Python, R, Positron, and Quarto working together.
Leo included detailed documentation in the GitHub repository, a great resource for anyone interested in market forecasting or multi-tool workflows. Thanks for sharing your work with the community, Leo!
We were recently joined by Thomas Lin Pedersen on the Data Science Lab, where he introduced the new ggsql package.
(Almost) immediately after the DS Lab, Dylan Poulsen wrote a blog post on exploring two years of swim data with ggsql! Dylan, we’re convinced you write blogs at the speed of ggsql.
We usually find these projects on social media. If you’re on LinkedIn, be sure to follow and tag Posit Open Source for us to share the amazing things you’re working on!
What’s next#
We’re taking a short break in July before returning with more community hangouts!
- On July 21, Gina Reynolds will join the Data Science Lab (a fun, chill time with live code) to show we can extend ggplot2 by creating our own custom extensions. Register here: https://pos.it/dslab
In the meantime, check out some past Data Science Lab episodes:
May 29, 2026
|
57 min
|
1.2k views
Async & Parallel R with {mirai} | Charlie Gao | Data Science Lab
The Data Science Lab is a live weekly call. Register at pos.it/dslab! Discord invites go out each week on lives calls. We’d love to have you!
The Lab is an open, messy space for learning and asking questions. Think of it like pair coding with a friend or two. Learn something new, and share what you know to help others grow.
On this call, Libby Heeren is joined by Charlie Gao, who walks through async and parallel programming using the mirai package for R. Charlie is the author of {mirai} and {mori}!
Charlie demonstrates how mirai lets you run R code in parallel across multiple cores or even distributed across remote machines. He covers the key differences between parallel and async programming, shows how to set up worker daemons (said like “demons”), scale resources dynamically, and connect to remote machines via SSH. Whether you’re running long computations, training models, or building Shiny apps, mirai helps you make the most of your computing resources without blocking your main R session:)
Hosting crew from Posit: Libby Heeren, Isabella Velasquez
Charlie Gao’s GitHub: https://github.com/shikokuchuo Charlie Gao’s Bluesky: https://bsky.app/profile/shikokuchuo.net Charlie Gao’s LinkedIn: https://www.linkedin.com/in/charliegao/ Charlie Gao’s Mastodon: https://fosstodon.org/@shikokuchuo
Resources mentioned in the video and chat: mirai package website: https://mirai.r-lib.org/ mirai GitHub repository: https://github.com/r-lib/mirai AskDeepSeek chatbot for mirai documentation: https://mirai.r-lib.org/ (click “ask deep wiki” button) mirai - Promises (Shiny and Plumber): https://mirai.r-lib.org/articles/v02-promises.html mirai - Serialization: https://mirai.r-lib.org/articles/v03-serialization.html mirai - OpenTelemetry: https://mirai.r-lib.org/articles/v05-opentelemetry.html mirai stop_mirai function: https://mirai.r-lib.org/reference/stop_mirai.html mirai skill for Claude Code: https://github.com/r-lib/mirai/blob/main/.claude/skills/mirai/SKILL.md Plumber2 package: https://plumber2.posit.co/ Daemon (computing) on Wikipedia: https://en.wikipedia.org/wiki/Daemon_(computing)
► Subscribe to Our Channel Here: https://bit.ly/2TzgcOu Follow Us Here: Website: https://www.posit.co Hangout: https://pos.it/dsh The Lab: https://pos.it/dslab LinkedIn: https://www.linkedin.com/company/posit-software Bluesky: https://bsky.app/profile/posit.co
Thanks for hanging out with us!
Timestamps of Questions / Topics: 00:00 Introduction 03:33 “What is async programming and how is it different from parallel?” 06:57 AskDeepSeek chatbot for the Mirai package 09:40 Setting up the Positron IDE with activity bar on top 15:25 “What was the motivation or need for developing Mirai?” 22:10 Mirai map function for parallel processing 25:25 “Do the contents of Mirai inherit definitions from the global environment?” 29:00 “What’s the difference between Mirai versus promises and future?” 31:50 Demonstrating sequential vs parallel processing 36:00 “Can you use Mirai with HPC?” 37:07 Dynamically scaling workers by adding and removing daemons 38:38 Setting up daemons with URLs for network connections 42:05 Launching workers over SSH to remote machines 43:09 SSH tunneling to connect workers without open ports 51:14 “Does Mirai allow R to perform the same thing as NumPy?” 51:54 “Does Mirai ship with some kind of task viewing dashboard?” 52:35 “Can we use parallel::detectCores() to see how many daemons we can use?” 53:58 “Would parallel processing be more useful than async processing in typical data science work?” 55:00 Mirai skill for Claude Code and AI agents
mirai
mori
plumber
plumber2
Positron
Jun 23, 2026
|
58 min
|
3.7k views
Data dictionaries, parquet, & Claude | Hadley Wickham | Data Science Lab
The Data Science Lab is a live weekly call. Register at pos.it/dslab! Discord invites go out each week on lives calls. We’d love to have you!
The Lab is an open, messy space for learning and asking questions. Think of it like pair coding with a friend or two. Learn something new, and share what you know to help others grow.
On this call, Libby Heeren is joined by Hadley Wickham, who walks through using data dictionaries with Claude Code to clean and document datasets effectively.
Hadley demonstrates a workflow using three files: a data cleaning script, a data dictionary in YAML format, and the final cleaned data as a Parquet file. He shows how Claude Code and MCP REPL can help generate and maintain data dictionaries that document what you know about your data, making it easier for both humans and AI agents to work with your datasets. Using the NYC elevators dataset as an example, he walks through data cleaning tasks like normalizing whitespace, handling missing values, fixing date formats, and investigating geocoding issues - all while keeping the data dictionary, cleaning script, and Parquet file in sync through git.
Hosting crew from Posit: Libby Heeren, Isabella Velasquez
Hadley Wickham’s GitHub: https://github.com/hadley Hadley Wickham’s Bluesky: https://bsky.app/profile/hadley.nz Hadley Wickham’s LinkedIn: https://www.linkedin.com/in/hadleywickham/
Resources mentioned in the video and chat: MCP REPL: https://github.com/posit-dev/mcp-repl Data Dictionary YAML Format Specification: https://github.com/hadley/data-dict.yaml Parquet files in R for Data Science: https://r4ds.hadley.nz/arrow.html#sec-parquet Elevators Dataset Used in Demo: https://github.com/EmilHvitfeldt/elevators Pointblank Package for Data Validation: https://posit-dev.github.io/pointblank/ Arrow R Book: https://arrowrbook.com/ Monaspace Font Family (with ligatures): https://monaspace.githubnext.com/ YAML Multiline Strings Reference: https://yaml-multiline.info/ UBC Course on Shiny with RAG and Parquet: https://ubc-mds.github.io/DSCI_532_vis-2_book/060-03-rag.html Tom Scott Video on Timezones: https://www.youtube.com/watch?v=-5wpm-gesOY Falsehoods Programmers Believe About Names: https://www.kalzumeus.com/2010/06/17/falsehoods-programmers-believe-about-names/ UTC Is Enough for Everyone Right: https://zachholman.com/talk/utc-is-enough-for-everyone-right Daniel Chen’s Cherry Blossom Analysis: https://chendaniely.github.io/posts/2026/2026-03-30-yvr-cherry-blossoms-marathon/ Project Drawdown Climate Impact Explorer: https://drawdown.org/explorer Green Coding Bookdown Resource: https://bookdown.org/content/d1e53ac9-28ce-472f-bc2c-f499f18264a3/ IBM Green Coding Topics: https://www.ibm.com/think/topics/green-coding Secret Elevator in Central Park Article: https://undercovernyc.home.blog/2021/02/08/a-secret-elevator-hidden-in-central-park/ Artificial Cave Beneath Central Park: https://gizmodo.com/an-artificial-cave-200-beneath-central-park-with-micha-1446538828
► Subscribe to Our Channel Here: https://bit.ly/2TzgcOu Follow Us Here: Website: https://www.posit.co Hangout: https://pos.it/dsh The Lab: https://pos.it/dslab LinkedIn: https://www.linkedin.com/company/posit-software Bluesky: https://bsky.app/profile/posit.co
Thanks for hanging out with us!
Timestamps of Questions / Topics: 00:00 Introduction 03:38 “Can you talk a little bit about what MCP is?” 05:42 Introducing the elevators dataset 07:00 Creating initial data dictionary with Claude 09:03 “Are there any cases where the CSV format is actually a better choice than Parquet?” 09:50 “What font do you use?” 12:02 Adding context from the readme to the data dictionary 14:02 “What is a good way to store data dictionaries along with datasets?” 14:38 “Is this particular data dict YAML format useful for projects with only one table of data?” 17:45 “Is Claude also going to decide when it’s a good time to make a commit?” 24:02 “Does MCP REPL work on a Windows machine and can one use other AI LLM for example ChatGPT with it?” 26:14 Converting date columns to proper date types 27:16 “Do you see a meaningful distinction between data dicts and data contracts?” 29:36 “How do you view your approach to data dictionaries and the development of pointblank?” 34:16 Eliminating placeholder values and using proper missing values 36:25 “Could you show off a diff of a Parquet file?” 38:25 Investigating geocodes and creating a map of elevators 40:20 Using a leaflet map to explore Central Park elevators 42:03 “Which model is Hadley using?” 43:55 Discussion of cost consciousness and environmental impact of LLMs 46:30 “Is there a way to quantify environmental and electrical costs?” 48:50 The mystery elevator in Central Park 54:23 “How do you know this is actually faster or more productive than just writing the code?” 55:45 The importance of deep knowledge of data in qualitative work
bookdown
bookdown.org
leaflet
pointblank
I’m a real person, and I would love to know how to make the Glimpse newsletter better! Find me on LinkedIn and Bluesky, or email me at isabella [dot] velasquez [at] posit.co.