



We are thrilled to release version 1.0.0 of the brulee package. brulee contains regression and classification models built using the torch framework. To install the package, use:
install.packages("brulee")
# or
pak::pak("brulee")New Models#
In the field of deep learning (DL), the term “tabular” refers to models that use common rectangular data sets, i.e., data in data frames or matrices. It specifically excludes raw images or unstructured text.
This release adds five new models:
- Residual networks (ResNet) via
brulee_resnet() - Regularization learning networks (RLN) with
brulee_rln() - AutoInt via
brulee_auto_int() - Self-Attention and Inter-sample Attention Transformer (Saint) using
brulee_saint() - Chronos2 foundational model for forecasting via
brulee_chronos()
These models share common argument names and have the same conventions as existing brulee models, such as brulee_mlp(). Many of these models incorporate modern neural network techniques, such as batch normalization, residual connections, and/or attention mechanisms.
For applications with large amounts of data, these modern techniques can make an already difficult optimization problem easier. The attention mechanisms also allow the model to be more expressive, leading to better performance.
Here’s an example using AutoInt. The data are simulated values with 10 predictors, a regression equation containing numerous interaction terms, and a true RMSE of 0.25.
The model was trained and evaluated on a random 10% of the data to determine early stopping. Training (using the ADAMw optimizer) stopped after 5 bad epochs and reverted to the estimates at epoch 7.
library(brulee)
library(tidymodels)
set.seed(83)
train_data <- sim_regression(2000, method = "hooker_2004")
test_data <- sim_regression(2000, method = "hooker_2004")
# Put the predictors on the same scale:
rec <-
recipe(outcome ~ ., data = train_data) |>
step_normalize(all_numeric_predictors())
# Set the R seed
set.seed(13)
# Set the torch seed (they don't need to be the same)
torch::torch_manual_seed(13)
autoint_fit <-
brulee_auto_int(
rec,
data = train_data,
num_embedding = 20,
verbose = TRUE
)epoch: 000, learn rate: 0.01, Loss (scaled): 1.06
epoch: 1, learn rate: 0.01, Loss (scaled): 0.179
epoch: 2, learn rate: 0.01, Loss (scaled): 0.144
epoch: 3, learn rate: 0.01, Loss (scaled): 0.12
epoch: 4, learn rate: 0.01, Loss (scaled): 0.103
epoch: 5, learn rate: 0.01, Loss (scaled): 0.115
epoch: 6, learn rate: 0.01, Loss (scaled): 0.102
epoch: 7, learn rate: 0.01, Loss (scaled): 0.101
epoch: 8, learn rate: 0.01, Loss (scaled): 0.109
epoch: 9, learn rate: 0.01, Loss (scaled): 0.101
epoch: 10, learn rate: 0.01, Loss (scaled): 0.108
epoch: 11, learn rate: 0.01, Loss (scaled): 0.112
epoch: 12, learn rate: 0.01, Loss (scaled): 0.116
autoplot(autoint_fit)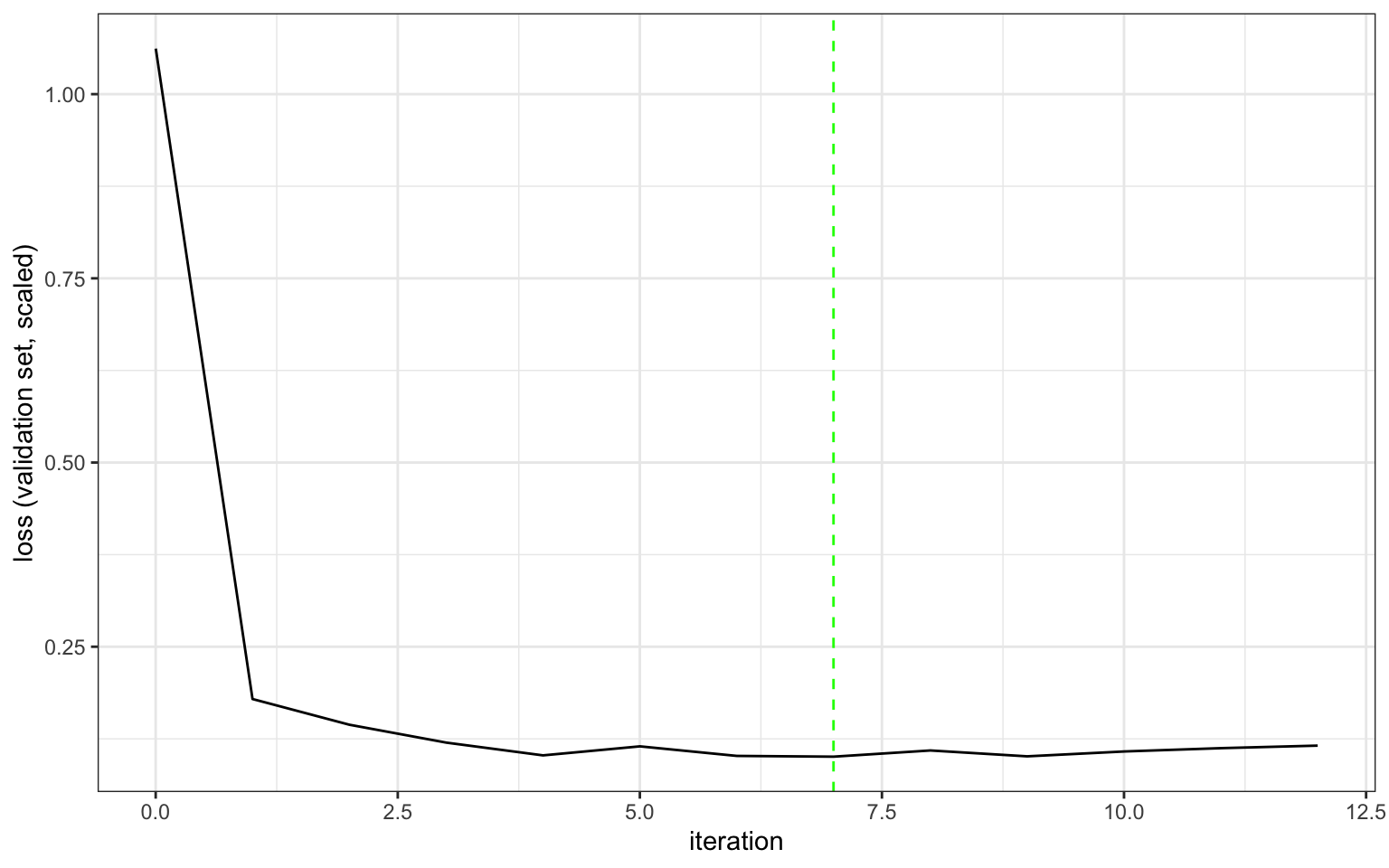
One new addition to brulee is a collection of summary() methods that print layer dimensions and the corresponding number of parameters. This model is complex but, by deep learning standards, is small:
summary(autoint_fit)AutoInt architecture
inputs: 10 (0 categorical, 10 numeric) | output dim: 1
Embedding layer
ContWeights(10 x 20) 200 params
Self-attention backbone (3 blocks, 2 heads)
Linear(20 -> 32) 672 params
MultiheadAttention(32, heads=2) 4,224 params
MultiheadAttention(32, heads=2) 4,224 params
MultiheadAttention(32, heads=2) 4,224 params
+ skip: Linear(20 -> 32) 672 params
ReLU 0 params
output: 10 embeddings of dim 32 (flattened: 320)
Output head
Linear(320 -> 1) 321 params
Total parameters: 14,537
How well does the model work on unseen data? Pretty well! The RMSE is fairly close to the best possible value.
test_pred <-
predict(autoint_fit, test_data) |>
bind_cols(test_data)
test_pred |>
ggplot(aes(outcome, .pred)) +
geom_point() +
geom_abline(col = "#8FDA04FF", lty = 2, linewidth = 1) +
geom_smooth(col = "#D84D16FF", se = FALSE) +
coord_fixed(ratio = 1)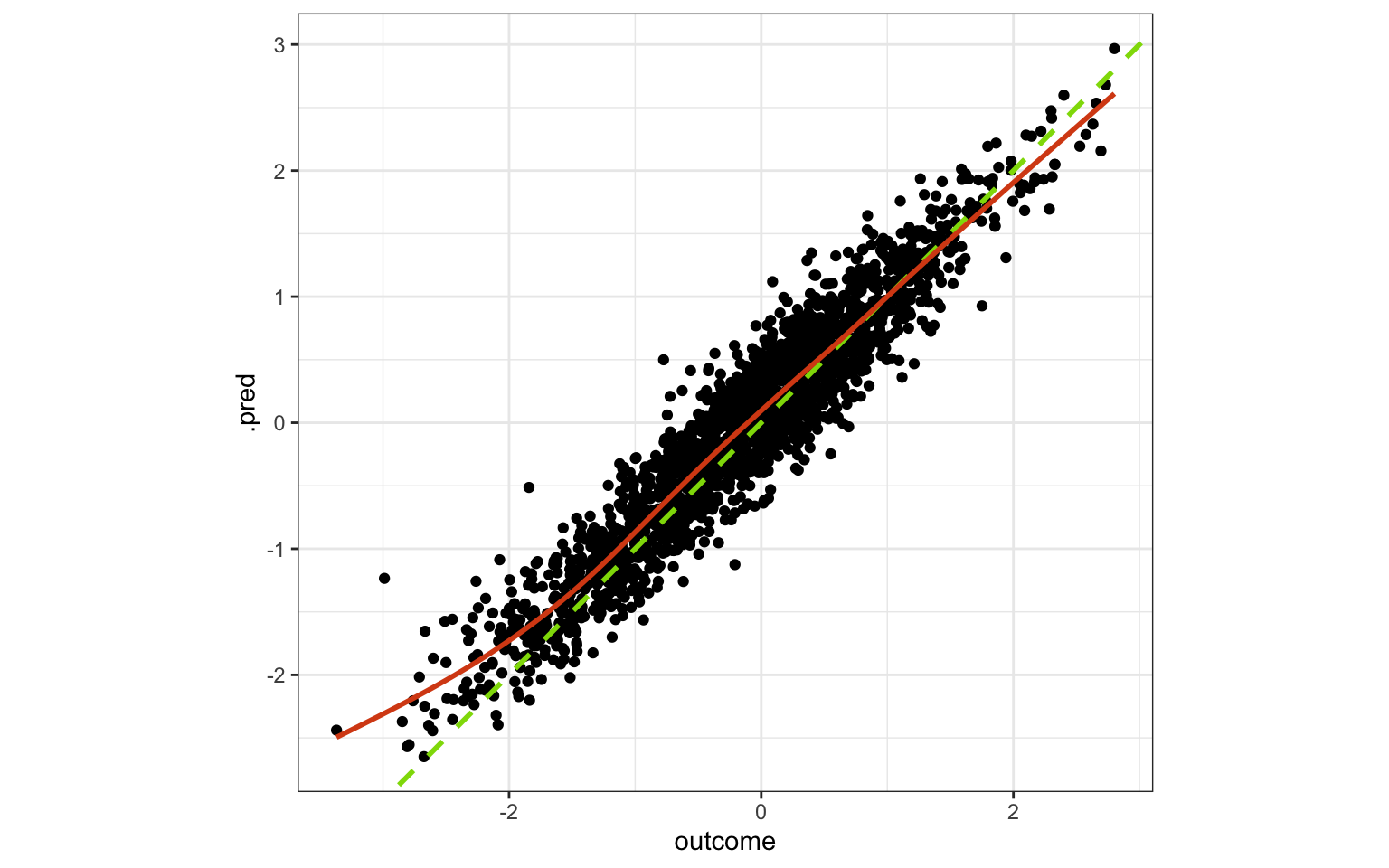
test_pred |> metrics(outcome, .pred)# A tibble: 3 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.316
2 rsq standard 0.898
3 mae standard 0.251
One important note: the Chronos model is a pretrained foundational model for forecasting. On its first use, it will download the model weights. These are about 200 MB in size and are cached locally, so this download should occur only once. This is similar to how our package for the TabPFN foundational model operates.
Numerical Changes#
This version breaks backward compatibility with previous versions, but for good reasons.
The first is to switch from 64-bit precision to 32-bit. This is a common strategy (and many DL models go down to 16- or 8-bit precision). This should make models run faster and have a smaller memory footprint, but the main reason was to enable GPU computations on Apple machines. Note, however, that for the data set and model sizes shown in the example above, there is limited efficiency gain on the GPU. Since the computational load is relatively light (by DL standards), the GPU spends most of its time idle, so it isn’t much faster than the CPU. With larger data sets and models like Saint or Chronos, there should be some time savings. Overall, though, there should be drastic memory savings when using the GPU compared to pure CPU computations.
We’ve also made an effort to increase the numerical stability of these methods. This involves a more pervasive gradient clipping strategy and, for classification models, a more numerically stable implementation of the cross-entropy objective function.
One small improvement concerns reproducibility. torch has some inconsistencies in how random numbers are handled for GPU computations. When initializing parameters for these models, the random numbers are generated on the CPU and then moved to the GPU. This allows the model to start from the same place independently of where the subsequent computations occur.
What’s Next#
For brulee, the next big step is an R torch implementation of the TabICL foundational model. This shows great promise but has a large computational footprint (in terms of code and system resources). Like Chronos, it will also require downloading pretrained model weights. We have a working version but are conducting additional testing before we release it.
Outside of brulee, we’re working on a parsnip interface to these models. Deep neural networks tend to have many tuning parameters, and many of them substantially affect model performance. The extension will include a function to make efficient space-filling designs for models with multiple hidden layers.
Thanks#
Banner image by Laura Peruchi.
Thanks to contributors @edgararuiz, @jeroenjanssens, @lizelgreyling, and @Wander03.



